
Kinesis Data stream의 제약조건 및 리샤딩 테스트
문서 목적
이 문서는 AWS Kinesis Data stream의 제약조건과 리샤딩에 대한 테스트 결과를 남기기 위해 작성하였다.
내용 중 실제 응답 결과에 대해 … 으로 표기한 부분은 가독성을 위해 생략한 것이다. 해당 부분 참고해 진행한다.
테스트 결론
테스트가 많고 문서의 가독성을 위해 결론을 서두에 적는다.
이 테스트에서는 AWS Kinesis의 제약조건을 테스트했으며 해당 제약조건은 다음과 같다.
-
AWS Kinesis putRecords API의 제약조건 중 Record 파라미터 갯수 제한
-
AWS Kinesis 단일 샤드에 대한 입력 제약조건
-
초당 1000개의 Record 입력
-
초당 1Mb의 Record 입력
-
-
AWS Kinesis 리샤딩 기능
-
단일 샤드에서 2개의 샤드로 분할 시 Record가 중단되지 않고 입력되는 지 테스트
-
2개의 샤드에서 단일 샤드로 병합 시 Record가 중단되지 않고 입력되는 지 테스트
-
위에 기술한 테스트 항목에 대해 테스트 진행 결과 AWS 공식문서에 기술된 AWS Kinesis의 제약조건은 유효함을 확인했으며 AWS Kinesis를 리샤딩할 시에도 Record가 정상적으로 중단 없이 입력됨을 확인했다.
다만, AWS Kinesis의 단일 샤드에 대한 제약요건 중 초당 1000개의 Record 입력은 putRecords API를 1회 호출해 테스트한 것이므로 완벽하게 확인을 하지 못했다. 이 부분은 AWS Kinesis를 테스트한 다른 문서를 통해 더 명확하게 확인할 수 있다.([테스트] Kinesis Data Stream - 샤드당 제약 조건 확인)
테스트 환경
-
테스트 리전: 서울 리전
-
테스트 관련 서비스:
-
Amazon Kinesis Data Stream
-
Amazon Kinesis Data Firsehose
-
Amazon Elasticsearch Service(이하 Amazon ES)
-
Amazon S3
-
Kinesis Data Firehose
Kinesis Stream +----------------------+
+---------+ +--------+ | Event-1 - Stream-1 | +--------+
| Sources |--------------->| Shard |----------| ... |---------------->| AWS S3 |
+---------+ data records +--------+ | Event-N - Stream-N | backup +--------+
Data Stream +----------------------+ Bucket
Delivery Streams
(Event Stream)
| +---------------+
| | Elasticsearch |
+---------------------------->| Cluster |<--->[Kibana]
indexing +---------------+ dashboard
테스트 환경 구성
Amazon ES 도메인
-
도메인 명:
-
Elasticsearch 6.5.4
-
인스턴스 구성
-
인스턴스 유형 : t2.small.elasticsearch (vCPU 1, Memory 2GiB)
-
인스턴스 개수 : 2
-
인스턴스별 일반 EBS(SSD) 10GB 각 1개
-
-
테스트 인덱스 : test-seongwoo-data-stream
Kinesis Data Stream 생성
테스트용 Data Stream을 아래와 같은 설정으로 생성하였다.
-
Kinesis Steram name : test-seongwoo-data-stream
-
Shard
-
샤드 수 : 1
-
쓰기 : 1 MB/초, 1000 레코드/초
-
읽기 : 2 MB/초
-
Kinesis Data Firehose Delivery Stream 생성
테스트용 Delivery Stream을 아래와 같은 설정으로 생성하였다. Source를 Kinesis Stream로 지정하였다.
-
Delivery Stream name : test-seongwoo-firehose
-
Source : Kinesis Stream
- Stream name : test-seongwoo-data-stream
-
Index : test-seongwoo-data-stream
-
Type : isc
-
No index rotation
-
Backup S3 bucket : sw-test123
-
Delivery Stream buffer conditions for Elasticsearch
-
buffer size : 5 MB
-
buffer interval : 60 seconds
-
-
IAM role(역할)
-
Amazon ES 도메인 ARN - firehose_delivery_role_seongwoo
-
직접 생성.
-
테스트: Delivery Stream 데이터 전송 및 S3 저장, 형태 확인
커넥츠 모바일에서 수집 될 것이라고 예상하는 데이터를 AWS Kinesis Data stream에 보내고 이를 delivery stream에서 Elasticsearch와 s3에 저장이 잘 되는 지 확인한다.
또한, S3에 어떠한 형태로 저장되는 지 확인한다.
{
"user_id": 3322,
"app_version": "v1.5.16(90)",
"device_id": "a03cd3d6-0b14-46e1-a2c8-18b1c86cf738",
"device_manufacturer": "LG",
"device_name": "LG G7 ThinQ",
"device_model": "LM-G710N",
"device_os": "Android",
"device_os_number": "8.0",
"event": "interest_service_click",
"interest_id": 1201,
"index": 1,
"interest_name": "관심사",
"interest_service_id": null,
"interest_service_type": "2",
"interest_service_name": "3",
"timestamp": "2019-04-30T07:30:00Z"
}
aws config, credential 설정 관련된 부분은 AWS CLI 구성 문서를 참고하도록 한다.
파이썬 가상환경을 구성하고 boto3 라이브러리를 설치한다.
$ python3 -m venv ./boto3_venv
$ source ./boto3_venv/bin/activate
$ pip3 install boto3
아래와 같은 파이썬 코드로 Kinesis Data Stream에 데이터를 전송하여 테스트 하였다.
import boto3
import json
import sys
def get_kinesis_client():
# Any clients created from this session will use credentials
# from the [stseoul] section of ~/.aws/credentials
# with stseoul profile.
session = boto3.Session()
kinesis = session.client("kinesis")
return kinesis
# Test list up Kinesis Data Streams
def list_streams():
kinesis = get_kinesis_client()
print("List Kinesis Streams")
response = kinesis.list_streams()
print(response["StreamNames"])
return response
def describe_stream(stream_name=None):
kinesis = get_kinesis_client()
print("Describe Kinesis Streams")
if stream_name is not None:
response = kinesis.describe_stream(StreamName=stream_name)
else:
response = kinesis.describe_stream(StreamName="test-seongwoo-data-stream")
print(response["StreamDescription"])
return response
# Test Record send to Data Streams
def put_record_to_data_stream():
print("Put record to Data Stream")
test_data = {
"user_id": 3322,
"app_version": "v1.5.16(90)",
"device_id": "a03cd3d6-0b14-46e1-a2c8-18b1c86cf738",
"device_manufacturer": "LG",
"device_name": "LG G7 ThinQ",
"device_model": "LM-G710N",
"device_os": "Android",
"device_os_number": "8.0",
"event": "interest_service_click",
"interest_id": 1201,
"index": 1,
"interest_name": "관심사",
"interest_service_id": None,
"interest_service_type": "2",
"interest_service_name": "3",
"timestamp": "2019-05-03T08:04:00Z"
}
kinesis = get_kinesis_client()
response = kinesis.put_record(
StreamName="test-seongwoo-data-stream",
Data=json.dumps(test_data, ensure_ascii=False),
PartitionKey="test-seongwoo-data-stream"
)
print(response)
def put_records_to_data_stream():
print("Put multiple records to Delivery Stream")
test_data_list = [
{
"user_id": 3322,
"app_version": "v1.5.16(90)",
"device_id": "a03cd3d6-0b14-46e1-a2c8-18b1c86cf738",
"device_manufacturer": "LG", "device_name": "LG G7 ThinQ", "device_model": "LM-G710N", "device_os": "Android", "device_os_number": "8.0",
"event": "interest_service_click",
"interest_id": 1101,
"index": 1,
"interest_name": "관심사", "interest_service_id": None, "interest_service_type": "2","interest_service_name": "5",
"timestamp": "2019-05-03T08:10:00Z"
},
{
"user_id": 3322,
"app_version": "v1.5.16(90)",
"device_id": "a03cd3d6-0b14-46e1-a2c8-18b1c86cf738",
"device_manufacturer": "LG", "device_name": "LG G7 ThinQ", "device_model": "LM-G710N", "device_os": "Android", "device_os_number": "8.0",
"event": "interest_service_click",
"interest_id": 1301,
"index": 1,
"interest_name": "관심사", "interest_service_id": None, "interest_service_type": "3","interest_service_name": "6",
"timestamp": "2019-05-03T08:20:00Z"
},
{
"user_id": 3322,
"app_version": "v1.5.16(90)",
"device_id": "a03cd3d6-0b14-46e1-a2c8-18b1c86cf738",
"device_manufacturer": "LG", "device_name": "LG G7 ThinQ", "device_model": "LM-G710N", "device_os": "Android", "device_os_number": "8.0",
"event": "interest_service_click",
"interest_id": 1201,
"index": 1,
"interest_name": "관심사", "interest_service_id": None, "interest_service_type": "2","interest_service_name": "3",
"timestamp": "2019-05-03T08:30:00Z"
}
]
# Data Stream에 batch로 넣을 데이터 구성
records_list = list()
for test_data in test_data_list:
records_list.append({
"Data": json.dumps(test_data, ensure_ascii=False),
"PartitionKey" : "test-seongwoo-data-stream"
}
)
kinesis = get_kinesis_client()
response = kinesis.put_records(
StreamName="test-seongwoo-data-stream",
Records=records_list
)
print(response)
def main():
arg = sys.argv[1:]
if "list_stream" in arg:
list_streams()
elif "desc_stream" in arg:
describe_stream()
elif "put" in arg:
put_record_to_data_stream()
elif "batch" in arg:
put_records_to_data_stream()
else:
print("Unsupported test operation")
print("Supported operations : ['list_stream', 'desc_stream', put', 'batch']")
if __name__ == "__main__":
main()
put_record() 메소드를 사용한 단일 데이터 전달과 put_record_batch() 메소드를 사용한 여러개의 데이터 전달에 대하여 동작을 테스트하였다.
테스트 코드 실행
(.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_steam.py desc_stream
Describe Kinesis Streams
{'StreamName': 'test-seongwoo-data-stream', ... }
(.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_steam.py list_stream
List Kinesis Streams
['test_kinesis', ... , 'test-seongwoo-data-stream']
(.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_steam.py put
Put record to Data Stream
{'ShardId': 'shardId-000000000000', ... }
(.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_steam.py batch
Put multiple records to Delivery Stream
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49599785146763097479697545100066493320130096649549643778', ... }
S3에 어떻게 저장되는 지 확인한다. 아래 내용은 공식 문서를 일부 발췌한 것이며 더 많은 내용은 공식 사이트에서 확인 할 수 있다.
Amazon S3 객체 이름 형식
Kinesis Data Firehose는 Amazon S3에 객체를 쓰기 전에 YYYY/MM/DD/HH 형식으로 UTC 시간 접두사를 추가합니다. 이 접두사는 버킷에 논리적 계층 구조를 생성하는데, 계층 구조 내에서 슬래시(/) 하나당 한 계층을 생성합니다. 사용자 지정 접두사를 지정하여 이 구조를 수정할 수 있습니다. 사용자 지정 접두사를 지정하는 방법은 Amazon S3 객체에 대한 사용자 지정 접두사 단원을 참조하십시오.
Amazon S3 객체 이름은 DeliveryStreamName-DeliveryStreamVersion-YYYY-MM-DD-HH-MM-SS-RandomString패턴을 따르는데, 여기에서 DeliveryStreamVersion는 1로 시작해 Kinesis Data Firehose 전송 스트림의 구성 변경이 이루어질 때마다 1씩 증가합니다. 전송 스트림 구성(예: S3 버킷 이름, 버퍼링 힌트, 압축, 암호화)을 변경할 수 있습니다. 이 작업은 Kinesis Data Firehose 콘솔 또는 UpdateDestination API 작업을 사용하여 수행할 수 있습니다.
S3는 다음과 같이 저장된다.
Key: 2019/09/24/05/test-seongwoo-firehose-1-2019-09-24-05-06-28-818e40dd-2318-4258-88cc-3c66a08eba10
{"user_id": "DUUUQMY-tx5Qy8e-DWtQW9q", "app_version": "v1.5.16(90)", "device_id": "2dlGCh-V3uaaM-qyyp3r-kWMnEZ-8SGAAD", "device_manufacturer": "Apple", "device_name": "Apple Iphone1", "device_model": "noZL-sFj5", "device_os": "IOS", "device_os_number": 46.0, "event": "my_page_serivce_click", "interest_id": "4569", "index": "1", "interest_name": "422", "interest_service_id": null, "interest_service_type": "33", "interest_service_name": "3335", "timestamp": "2019-07-18T19:43:40Z"}{"user_id": "an0s9wG-xgyregq-5XwO4BR", "app_version": "v7.74.23(55)", "device_id": "6gBC5m-r9SIhn-RGJ4bU-rMJPSt-gPqE6J", "device_manufacturer": "Huawei", "device_name": "Huawei Nova3", "device_model": "M2A6-HG7q", "device_os": "Android", "device_os_number": 77.0, "event": "my_page_serivce_click", "interest_id": "2342", "index": "3", "interest_name": "343", "interest_service_id": null, "interest_service_type": "545", "interest_service_name": "3", "timestamp": "2019-04-12T20:24:16Z"}
...
하략
테스트: AWS Kinesis putRecords API 입력 제한 테스트
AWS Kinesis Data stream service API의 putRecords 제한 조건은 다음과 같다. 이 내용은 공식 사이트에서 확인 할 수 있다.
Each PutRecords request can support up to 500 records. Each record in the request can be as large as 1 MiB, up to a limit of 5 MiB for the entire request, including partition keys. Each shard can support writes up to 1,000 records per second, up to a maximum data write total of 1 MiB per second.
테스트는 다음과 같이 진행한다. 아래의 제약조건을 제외한 나머지 제약조건에 대한 부분(1개의 레코드에 대한 용량이 1Mb를 넘을 수 없다는 것, 1개 API 호출 시 모든 파라미터의 용량 합이 5메가를 넘을 수 없다는 것)은 실제 운용 시 해당 제약조건을 초과하거나 근접하게 운용하는 일이 발생할 확률이 낮을 것이라 생각해 제외했다.
테스트: putRecords API의 Records 파라미터의 Record 갯수가 500개 이상을 입력했을 경우
테스트한 코드는 위에 첨부된 “Kinesis Data Stream test python code sample” Code block에 있는 것을 부분 수정해 진행했다. 위의 코드 중 put_Records의 파라미터만 바꿔 진행한 것이므로 따로 코드를 남겨놓지 않는다.
테스트를 위해 putRecords API에 Record 1000개를 넣어 AWS Kinesis에 입력했다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
결과는 다음과 같다
start data generator
Put record to Data Stream
response: {'ShardId': 'shardId-000000000000', ... }
Successfully put record
Put multiple records to Delivery Stream
Traceback (most recent call last):
File "test_sender_kinesis_data_stream_seongwoo.py", line 150, in <module>
main()
File "test_sender_kinesis_data_stream_seongwoo.py", line 145, in main
put_records_to_data_stream(1000, 3)
File "test_sender_kinesis_data_stream_seongwoo.py", line 136, in put_records_to_data_stream
response = send_records_to_kinesis(record_list)
File "test_sender_kinesis_data_stream_seongwoo.py", line 107, in send_records_to_kinesis
Records=records_list
File "/Users/st/test/kinesis_test_poc/.venv/lib/python3.7/site-packages/botocore/client.py", line 357, in _api_call
return self._make_api_call(operation_name, kwargs)
File "/Users/st/test/kinesis_test_poc/.venv/lib/python3.7/site-packages/botocore/client.py", line 661, in _make_api_call
raise error_class(parsed_response, operation_name)
botocore.exceptions.ClientError: An error occurred (ValidationException) when calling the PutRecords operation: 1 validation error detected: Value '[PutRecordsRequestEntry(data=java.nio.HeapByteBuffer[pos=0 lim=503 cap=503], explicitHashKey=null,
partitionKey=test-seongwoo-data-stream), PutRecordsRequestEntry(data=java.nio.HeapByteBuffer[pos=0 lim=521 cap=521], explicitHashKey=null, partitionKey=test-seongwoo-data-stream), PutRecordsRequestEntry(data=java.nio.HeapByteBuffer[pos=0 lim=503 cap=503], explicitHashKey=null,
...
같은 형식의 내용이 반복되어 중략한다.
...
partitionKey=test-seongwoo-data-stream), PutRecordsRequestEntry(data=java.nio.HeapByteBuffer[pos=0 lim=518 cap=518], explicitHashKey=null, partitionKey=test-seongwoo-data-stream)]' at 'records' failed to satisfy constraint: Member must have length less than or equal to 500
Record 갯수를 1000개로 넣었을 때, AWS Kinesis API putRecords는 오류가 발생했으며 S3를 확인 결과 아무런 데이터도 기록되지 않았다.
또한, AWS Kinesis 모니터링 콘솔에서도 데이터 입력이 0으로 표시되었다. 이 결과를 통해 다음과 같은 사실을 알 수 있다.
- 500개를 초과한 Record를 putRecords API에 파라미터로 넣어 API 호출 시 에러가 발생하며 해당 Records는 AWS Kinesis에 전부 입력되지 않는다.
1000개를 넣었을 경우 에러가 발생한다는 것을 확인했다. 오류 메시지를 보면 “put_records API의 Member는 500개와 동등하거나 낮은 수준이여야 한다”라는 부분이 있다. 그래서 확인해보기 위해 records 갯수를 500개로 바꿔 진행했다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
결과는 다음과 같다.
start data generator
Put multiple records to Delivery Stream
size record: 4272
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49600332740223402687238218016128099187294154588323578050', ...
...
중략
...
... 'content-length': '55535'}, 'RetryAttempts': 0}}
time : 0.7376766204833984
end data generator
S3에 제대로 데이터가 저장되어 있는 지 확인한다. S3에 정상적으로 저장되었는 지 확인하기 위해 Test Key의 Value를 데이터 순서에 따라 1씩 증가하게 넣었다.
{"test": 0}{"test": 1}{"test": 2}{"test": 3}{"test": 4}{"test": 5}{"test": 6}{"test": 7}{"test": 8}{"test": 9}{"test": 10}{"test": 11}{"test": 12}{"test": 13}{"test": 14}{"test": 15}{"test": 16}{"test": 17}{"test": 18}{"test": 19}{"test": 20}{"test": 21}{"test": 22}{"test": 23}{"test": 24}{"test": 25}{"test": 26}{"test": 27}{"test": 28}{"test": 29}{"test": 30}{"test": 31}{"test": 32}{"test": 33}{"test": 34}{"test": 35}{"test": 36}{"test": 37}{"test": 38}{"test": 39}{"test": 40}{"test": 41}{"test": 42}{"test": 43}{"test": 44}{"test": 45}{"test": 46}{"test": 47}{"test": 48}{"test": 49}{"test": 50}{"test": 51}{"test": 52}{"test": 53}{"test": 54}{"test": 55}{"test": 56}{"test": 57}{"test": 58}{"test": 59}{"test": 60}{"test": 61}{"test": 62}{"test": 63}{"test": 64}{"test": 65}{"test": 66}{"test": 67}{"test": 68}{"test": 69}{"test": 70}{"test": 71}{"test": 72}{"test": 73}{"test": 74}{"test": 75}{"test": 76}{"test": 77}{"test": 78}{"test": 79}{"test": 80}{"test": 81}{"test": 82}{"test": 83}{"test": 84}{"test": 85}{"test": 86}{"test": 87}{"test": 88}{"test": 89}{"test": 90}{"test": 91}{"test": 92}{"test": 93}{"test": 94}{"test": 95}{"test": 96}{"test": 97}{"test": 98}{"test": 99}{"test": 100}{"test": 101}{"test": 102}{"test": 103}{"test": 104}{"test": 105}{"test": 106}{"test": 107}{"test": 108}{"test": 109}{"test": 110}{"test": 111}{"test": 112}{"test": 113}{"test": 114}{"test": 115}{"test": 116}{"test": 117}{"test": 118}{"test": 119}{"test": 120}{"test": 121}{"test": 122}
...
중략
...
{"test": 497}{"test": 498}{"test": 499}
API 응답 메세지의 FailedRecordCount가 0이라는 것과 S3에 정상적으로 입력된 데이터 로그를 통해 putRecords API가 오류 메시지 없이 정상적으로 실행 되었다는 것을 확인할 수 있다.
위의 결과를 통해 다음과 같은 사실을 알 수 있다.
- Kinesis API putRecords 제약조건은 AWS Kinesis API 공식 개발문서에 있는 제약 조건과 같으며 500개 이하까지만 입력이 가능하다.
테스트: AWS Kinesis Data Stream 초당 1000개 또는 1MB 전송
AWS Kinesis Data stream의 Input 제한 조건은 다음과 같다. 일부를 발췌해 아래에 기술하였으며 공식 사이트 링크를 통해 더 많은 내용을 확인할 수 있다.
Kinesis Data Streams 제한
Amazon Kinesis Data Streams에는 다음과 같은 스트림 및 샤드 제한이 적용됩니다.
-
한 스트림 또는 한 계정에서 사용할 수 있는 샤드 수는 상한이 없습니다. 일반적으로 한 워크로드에는 수천 개의 샤드가 하나의 스트림에 포함되어 있습니다.
-
단일 계정에서 사용할 수 있는 스트림 수는 상한이 없습니다.
-
개별 샤드는 초당 1MiB의 데이터(파티션 키 포함) 또는 초당 레코드 1,000개를 수집해 쓸 수 있습니다. 마찬가지로, 스트림을 샤드 5,000개로 확장하면 해당 스트림은 초당 5GiB나 레코드 5백만 개를 수집할 수 있습니다. 추가 수집 용량이 필요한 경우 AWS Management 콘솔 또는UpdateShardCount API를 사용하여 스트림의 샤드 수를 쉽게 확장할 수 있습니다.
-
AWS 리전 미국 동부(버지니아 북부), 미국 서부(오레곤) 및 EU(아일랜드)의 기본 샤드 제한은 500개이고 다른 모든 리전의 기본 샤드 제한은 200개입니다.
-
Base64 인코딩 전 레코드의 데이터 페이로드 최대 크기는 1MiB입니다.
-
GetRecords는 단일 샤드에서 호출당 최대 10MiB 데이터와 호출당 최대 레코드 10,000개를 검색할 수 있습니다. 모든 GetRecords 호출은 1개의 읽기 트랜잭션으로 간주됩니다.
-
각 샤드는 초당 최대 5개의 읽기 트랜잭션을 지원합니다. 각 읽기 트랜잭션은 최대 10,000개의 레코드를 제공하며, 트랜잭션당 상한은 10MiB입니다.
-
각 샤드는 GetRecords를 통해 초당 2MiB의 최대 총 데이터 읽기 속도를 지원합니다. GetRecords 호출이 10MiB를 반환하면, 다음 5초 안에 이루어지는 호출에서 예외가 발생합니다.
-
스트림당 최대 20명의 소비자를 등록하여 향상된 팬아웃을 사용할 수 있습니다.
이 제약 조건 중 Data stream 쓰기 제약조건에 대해 테스트를 진행한다. 테스트는 다음과 같이 진행한다.
-
초당 1000개의 Record 입력
-
초당 1Mb의 Record 입력
테스트: 초당 1000개의 Record 입력
테스트한 코드는 위에 첨부된 “Kinesis Data Stream test python code sample” Code block에 있는 것을 부분 수정해 진행했다. 위의 코드 중 putRecords의 파라미터만 바꿔 진행한 것이므로 따로 코드를 남겨놓지 않는다.
테스트 하기 위해 Python Time 모듈을 이용해 처음 AWS Kinesis API 호출부터 AWS Kinesis API Response를 받는 시점까지 측정했다.
AWS Kinesis putRecords의 Record 파라미터 갯수 제약조건으로 인해 1회 호출 시 Record 500개를 Kinesis에 입력했다. 3회 반복해 총 1500개의 Records를 입력했다. 각 각의 Record의 value들은 0부터 499까지의 값을 차례대로 부여했다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
결과는 다음과 같다
start data generator
Put multiple records to Delivery Stream
size record_list: 4272
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49599785146763097479698356765197192885873289808377282562', ... ,'ShardId': 'shardId-000000000000'},
중략
...
'HTTPHeaders': {'x-amzn-requestid': 'ea1bdd1e-d9b6-02ee-bc0f-21cacc407fd6', 'x-amz-id-2': '+n7mT++dLSc28TxENLwUQSx4nT99aM9EWnP3IxiGC43u63LUpEwJr3ClKIGY2cPkgHmzTGsNOa7TK5CqvCJyXOcHkXg+k1HX', 'date': 'Mon, 7 Oct 2019 08:43:00 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '55535'}, 'RetryAttempts': 0}}
size record_list: 4272
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49599785146763097479698356765996292852638559692858064898', ..., 'ShardId': 'shardId-000000000000'},
중략
...
'HTTPStatusCode': 200, ... 'ShardId': 'shardId-000000000000'},
중략
...
'HTTPStatusCode': 200, ... 'content-length': '55535'}, 'RetryAttempts': 0}}
time : 0.46463775634765625
end data generator
결과를 통해 0.46초안에 AWS Kinesis에 1500개의 Records가 입력되었다는 것을 확인할 수 있다.
S3에 제대로 데이터가 저장되어 있는 지 확인한다.
아래의 결과는 보기 쉽게 중간의 부분을 생략하였으며 실제는 줄바꿈 없이 연속되어 Record가 입력되었다.
{"test": 0}{"test": 1}{"test": 2}{"test": 3}{"test": 4}{"test": 5}
...
{"test": 497}{"test": 498}{"test": 499}{"test": 0}{"test": 1}{"test": 2}{"test": 3}{"test": 4}{"test": 5}
...
{"test": 497}{"test": 498}{"test": 499}{"test": 0}{"test": 1}{"test": 2}{"test": 3}{"test": 4}{"test": 5}
...
{"test": 497}{"test": 498}{"test": 499}
API 응답 메세지의 FailedRecordCount가 0이라는 것과 S3에 정상적으로 입력된 데이터 로그를 통해 putRecords API가 오류 메시지 없이 정상적으로 실행 되었다는 것을 확인할 수 있다. S3의 로그는 0~499까지의 값이 3번 반복됨을 확인할 수 있다.
위의 결과를 통해 다음과 같은 사실을 알 수 있다.
- AWS Kinesis Data stream은 초당 1000개 이상의 입력을 받을 수 있다. 그러나 문서에 AWS Kinesis 입력 제한이 초당 1000개이므로 1000개까지만 입력하는 것을 권장한다.
테스트: 초당 1Mb의 Record 입력
테스트한 코드는 위에 첨부된 “Kinesis Data Stream test python code sample” Code block에 있는 것을 부분 수정해 진행했다. 위의 코드 중 putRecords의 파라미터만 바꿔 진행한 것이므로 따로 코드를 남겨놓지 않는다.
Record 갯수는 20개씩 보냈으며 Record 한개의 key의 Value에 list로 묶은 문자열을 보냈다. 보낸 Record를 파일로 남겨 용량을 측정했다. 각 각의 Record의 value들은 0부터 8999까지의 값을 차례대로 부여했다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
결과는 다음과 같다.
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49599785146763097479698550723467690569786003296706625538', 'ShardId': 'shardId-000000000000'}, ... 'x-amz-id-2': 'GogLEyz7V3+EFIneHaCt+mFeP+XscMmpKgF5BUZttI2j4PeejACvIhqFK0UrMtkeL2dLbf4GEaco/F4/ersaDeALCvjNpb5s', 'date': 'Thu, 10 Oct 2019 09:18:56 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '2255'}, 'RetryAttempts': 0}}
time : 0.31870388984680176
S3에 제대로 데이터가 저장되어 있는 지 확인한다. S3에 정상적으로 저장되었는 지 확인하기 위해 Test Key의 Value를 데이터 순서에 따라 1씩 증가하게 넣었다.
{"test": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93,
...
중략
...
8954, 8955, 8956, 8957, 8958, 8959, 8960, 8961, 8962, 8963, 8964, 8965, 8966, 8967, 8968, 8969, 8970, 8971, 8972, 8973, 8974, 8975, 8976, 8977, 8978, 8979, 8980, 8981, 8982, 8983, 8984, 8985, 8986, 8987, 8988, 8989, 8990, 8991, 8992, 8993, 8994, 8995, 8996, 8997, 8998, 8999]}
API 응답 메세지의 FailedRecordCount가 0이라는 것과 S3에 정상적으로 입력된 데이터 로그를 통해 putRecords API가 오류 메시지 없이 정상적으로 실행 되었다는 것을 확인할 수 있다. S3의 로그를 통해 0~8999까지의 값이 정상적으로 기록된 것을 확인할 수 있다.
보낸 Records를 저장한 File의 용량은 1.1Mb이다. 0.318초의 응답시간안에 1.1Mb를 보냈으니 초당 1Mb 입력이 되는듯 하지만 실제 로컬 맥의 시간과 AWS Kinesis의 시간이 동기화되어 처리가 되지 않으므로 명확하게 테스트 되지 않는 부분이 있어 더 많은 데이터를 보내어 테스트 하려고 한다.
20개, 용량은 1.1Mb Records를 3번 AWS Kinesis에 입력한다. 위와 다른 점은 Record의 key, value 값 중 Test key의 Value를 ‘a’로 했다. 그 이유는 숫자를 증가시켜 입력할 경우 처리 속도가 느려 원하는 성능이 나오지 않기 때문이다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
결과는 다음과 같다.
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49599785146763097479698551505547190720701591040607387650', 'ShardId': 'shardId-000000000000'}, {'SequenceNumber': '49599785146763097479698551505548399646521205669782093826', 'ShardId': 'shardId-000000000000'}, {'SequenceNumber': '49599785146763097479698551505549608572340820298956800002', 'ShardId': 'shardId-000000000000'}, {'SequenceNumber': '49599785146763097479698551505550817498160434928131506178', 'ShardId': 'shardId-000000000000'}, {'SequenceNumber': '49599785146763097479698551505552026423980049557306212354', ... 'content-length': '2477'}, 'RetryAttempts': 0}}
time : 2.4904608726501465
S3에 제대로 데이터가 저장되어 있는 지 확인했으나 ‘a’값을 일일이 세어볼 수 없으므로 해당 리턴 메시지로 파악을 진행한다.
리턴 메시지로 봤을 때, 총 60개의 Records 중 17개가 실패했다. 총 용량 3.3Mb이며 완료 시간은 2.49초이다. 17개는 약 0.937Mb이며 실패한 용량을 제외한 Records의 용량은 2.365Mb이다.
이를 수행한 시간으로 나눠 초당 처리한 용량을 계산하면 0.9497Mb이며 여러 가지 변수에 의한 오차를 감안하면 초당 약 1Mb에 근접한다고 볼 수 있다.
위의 결과를 통해 AWS Kinesis의 초당 1Mb 제약조건이 유효함을 확인했다.
테스트: AWS Kinesis Data Stream 리샤딩 기능 테스트
AWS Kinesis 개발자 문서에서는 Kinesis data stream이 리샤딩 기능을 지원한다고 명시되어 있다. AWS Kinesis를 Production 환경에서 운용할 경우 리샤딩중에도 데이터가 입력되는 경우가 생길 수 있어 테스트를 진행한다.
이 테스트는 아래와 같은 경우를 테스트하기 위해 실시한다.
-
샤드가 1개에서 2개로 분할 되었을 때 분할 과정에서 데이터가 정상적으로 입력이 되는 지 테스트한다.
-
샤드가 2개에서 1개로 병합 되었을 때 병합 과정에서 데이터가 정상적으로 입력이 되는 지 테스트한다.
테스트: 샤드 1개에서 2개로 분할
테스트는 아래와 같은 순서로 진행된다. 테스트 데이터 입력이 제대로 되었는 지 확인을 위해 Value값은 1부터 차례대로 1씩 증가하게 값을 입력했다.
-
AWS Kinesis 샤드 1개로 구성한 후 0.5초마다 500개의 Records를 AWS Kinesis에 100회 반복해 입력한다.
-
입력 과정 중 AWS Kinesis 콘솔에서 샤드를 1개에서 2개로 변경한다.
-
변경이 정상적으로 끝난 것을 콘솔에서 확인 후 S3에 남겨진 로그와 API 리턴 메시지를 통해 정상적 입력이 되었는 지 확인한다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
다음은 AWS Kinesis 콘솔에서 샤드 1개임을 확인한 스크린샷이다.

결과는 다음과 같다.
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': ... 'ShardId': 'shardId-000000000006'}, {'SequenceNumber':
...
중략
...
2019 08:58:54 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '55535'}, 'RetryAttempts': 0}}
time : 73.51617002487183
응답 메시지가 너무 길어 중간에 생략하였다.
메시지를 통해 모든 Records이 정상적으로 입력 되었음을 확인했다.
다음은 성공적으로 샤드가 변경되었다는 콘솔 메시지를 캡쳐한 사진이다.
변경 후 Open shards는 2개가 되었으며 Closed shards가 6에서 7로 1이 더해진 것을 알 수 있다.
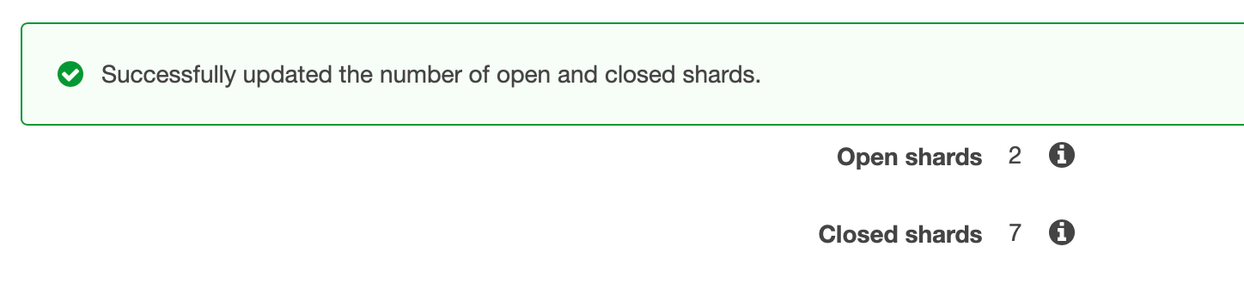
로그는 2개의 파일에 나눠 기록되었다. 해당 파일의 키값은 다음과 같다.
2019/10/11/09/test-seongwoo-firehose-2-2019-10-11-09-23-02-b3a6dd32-fb83-419f-bb6d-db30becb3d14, 2019/10/11/09/test-seongwoo-firehose-2-2019-10-11-09-22-43-de40823e-7801-470b-b62e-333c3f8c176a
아래는 위에 기술한 2개 파일의 S3 로그 메시지이다.
{"test": 0}{"test": 1}{"test": 2}{"test": 3}{"test": 4}{"test": 5}{"test": 6}{"test": 7}{"test": 8}{"test": 9}{"test": 10}{"test": 11}{"test": 12}{"test": 13}{"test": 14}{"test": 15}{"test": 16}{"test": 17}{"test": 18}{"test": 19}{"test": 20}{"test": 21}{"test": 22}{"test": 23}
...
중략
...
{"test": 49990}{"test": 49991}{"test": 49992}{"test": 49993}{"test": 49994}{"test": 49995}{"test": 49996}{"test": 49997}{"test": 49998}{"test": 49999}
API 응답 메세지의 FailedRecordCount가 0이라는 것과 S3에 정상적으로 입력된 데이터 로그를 통해 putRecords API가 오류 메시지 없이 정상적으로 실행 되었다는 것을 확인할 수 있다.
위의 결과를 통해 샤드가 1개에서 2개로 분할되는 과정에서 정상적으로 데이터가 AWS Kinesis에 입력되고 있음을 확인할 수 있다.
테스트: 샤드 2개에서 1개로 병합
테스트는 아래와 같은 순서로 진행된다. 테스트 데이터 입력이 제대로 되었는 지 확인을 위해 Value값은 1부터 차례대로 1씩 증가하게 값을 입력했다.
-
AWS Kinesis 샤드 1개로 구성한 후 0.5초마다 500개의 Records를 AWS Kinesis에 100회 반복해 입력한다.
-
입력 과정 중 AWS Kinesis 콘솔에서 샤드를 2개에서 1개로 변경한다.
-
변경이 정상적으로 끝난 것을 콘솔에서 확인 후 S3에 남겨진 로그와 API 리턴 메시지를 통해 정상적 입력이 되었는 지 확인한다.
실행 명령은 다음과 같다.
$ (.venv) ➜ kinesis_test_poc python test_sender_kinesis_data_stream_seongwoo.py > test.log 2>&1
다음은 AWS Kinesis 콘솔에서 샤드 2개임을 확인한 스크린샷이다.

결과는 다음과 같다.
{'FailedRecordCount': 0, 'Records': [{'SequenceNumber': '49600331525144999800098489595455988878940239397411356770', 'ShardId': 'shardId-000000000006'}
...
중략
...
2019 08:58:54 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '55535'}, 'RetryAttempts': 0}}
time : 72.90893507003784
응답 메시지가 너무 길어 중간에 생략하였다.
메시지를 통해 모든 Records이 정상적으로 입력 되었음을 확인했다.
다음은 성공적으로 샤드가 변경되었다는 콘솔 메시지를 캡쳐한 사진이다.
변경 후 Open shards는 1개가 되었으며 Closed shards가 10에서 12로 2가 더해진 것을 알 수 있다.

로그는 2개의 파일에 나눠 기록되었다. 해당 파일의 키값은 다음과 같다.
2019/10/11/09/test-seongwoo-firehose-2-2019-10-11-09-23-02-b3a6dd32-fb83-419f-bb6d-db30becb3d14, 2019/10/11/09/test-seongwoo-firehose-2-2019-10-11-09-22-43-de40823e-7801-470b-b62e-333c3f8c176a
아래는 위에 기술한 2개 파일의 S3 로그 메시지이다.
{"test": 0}{"test": 1}{"test": 2}{"test": 3}{"test": 4}{"test": 5}{"test": 6}{"test": 7}{"test": 8}{"test": 9}{"test": 10}{"test": 11}{"test": 12}{"test": 13}{"test": 14}{"test": 15}{"test": 16}{"test": 17}{"test": 18}{"test": 19}{"test": 20}{"test": 21}{"test": 22}{"test": 23}
...
중략
...
{"test": 49990}{"test": 49991}{"test": 49992}{"test": 49993}{"test": 49994}{"test": 49995}{"test": 49996}{"test": 49997}{"test": 49998}{"test": 49999}
API 응답 메세지의 FailedRecordCount가 0이라는 것과 S3에 정상적으로 입력된 데이터 로그를 통해 putRecords API가 오류 메시지 없이 정상적으로 실행 되었다는 것을 확인할 수 있다.
위의 결과를 통해 샤드가 1개에서 2개로 분할되는 과정에서 정상적으로 데이터가 AWS Kinesis에 입력되고 있음을 확인할 수 있다.
댓글남기기