
AWS Kinesis firehose에 여러 개의 Records를 list로 만들어서 lambda로 변환하기
목적
이 문서는 여러 개의 Record를 리스트에 담아 하나의 레코드로 만들어 보낸 후 AWS Kinesis Data Firehose에 설정된 Lambda를 함수를 트리거해서 리스트에 담겨진 여러 개의 Record를 뽑아내어 변환하는 것에 관한 테스트 내용을 정리하고 공유하기 위해 작성되었다.
테스트 환경
테스트 환경은 다음과 같다.
AWS
-
AWS Lambda
-
AWS Kinesis Data stream
-
AWS Kinesis Firehose
-
Python 2.7
로컬 환경
-
iMac MacOS Catalina
-
Python 3.7
테스트 컴포넌트 구조 및 테스트 진행 순서
테스트가 실행되는 환경은 다음과 같은 구조로 구성되어 있다. 아래의 컴포넌트를 구성하는 것은 AWS 공식 문서를 참고해 진행한다. 이후 단계부터는 이미 구성되어있다는 가정하에 진행한다.
|
<Data generator Layer> | <Data Collect/Process/Store Layer>
|
+-------------------+ |
| Data generator | | Kinesis Data Stream Kinesis Firehose
| +----------------+ send data | +---------------------+ Lambda transform +------------------+ save +----+
| data | Boto3 library |-----------------|--->| Shard 1 |--------------------| Delivery Streams |---------->| S3 |
| +----------------+ putRecord | +---------------------+ data +------------------+ +----+
| | |
+-------------------+ |
|
|
|
테스트는 다음과 같은 순서로 진행된다.
-
Data generator 생성 및 실행한다.
-
Lambda 생성 및 코드를 등록 한다.
-
생성한 Lambda를 Firehose에 트리거로 설정 한다.
-
Data generator 실행하고 데이터를 전송하여 최종적으로 S3에 데이터가 원하는 형태로 저장 되었는지 확인한다.
여러 개의 Record를 1개의 List로 만들어 Data stream에 보내기 테스트
테스트 데이터
데이터는 다음과 같은 형태로 구성된다. 테스트에선 쉬운 확인을 위해 아래와 같은 형태로 10개의 Record를 List에 담아 만들어 1개의 Record로 보낸다.
{
"data":
[
{"board_id": 504060, "playtime": 2, "user_id": 115790, "timestamp": "2019-09-22T11:46:47Z", "interest": "test_fluentd_firehose"},
{"board_id": 504060, "playtime": 2, "user_id": 115790, "timestamp": "2019-09-22T11:46:47Z", "interest": "test_fluentd_firehose"},
{"board_id": 504060, "playtime": 2, "user_id": 115790, "timestamp": "2019-09-22T11:46:47Z", "interest": "test_fluentd_firehose"},
{"board_id": 504060, "playtime": 2, "user_id": 115790, "timestamp": "2019-09-22T11:46:47Z", "interest": "test_fluentd_firehose"},
...
생략
...
]
}
Data generator 생성 및 실행하기
여러 개의 Record를 1개의 List로 만들어 AWS Kinesis Data stream에 보내기 위해 다음과 같은 작업을 수행한다.
-
프로젝트 폴더를 생성하고 가상환경을 생성한다.
-
가상환경을 활성화한다.
-
Data generator를 수정하고 실행한다.
-
실행 결과를 확인한다.
$ virtualenv .venv
$ source .venv/bin/activate
$ pip install boto3
from datetime import datetime
import string
import time
from multiprocessing import Pool
from random import *
import random
from datetime import timedelta, datetime
import json
import boto3
import sys
def get_kinesis_client():
# Any clients created from this session will use credentials
# from the [stseoul] section of ~/.aws/credentials
# with stseoul profile.
session = boto3.Session()
kinesis = session.client("kinesis")
return kinesis
def random_date(start, end):
"""
This function will return a random datetime between two datetime
objects.
"""
delta = end - start
int_delta = (delta.days * 24 * 60 * 60) + delta.seconds
random_second = randrange(int_delta)
return start + timedelta(seconds=random_second)
def make_datetime_now():
d1 = datetime.strptime('1/1/2019 1:30 PM', '%m/%d/%Y %I:%M %p')
d2 = datetime.strptime('12/29/2019 4:50 AM', '%m/%d/%Y %I:%M %p')
d3 = random_date(d1, d2)
d3 = str(d3)
random_date_string = d3[0:10] + 'T' +d3[11:]+'Z'
return random_date_string
def make_random_number(start, end):
random_number = randint(start, end)
return random_number
def make_datum():
board_id = make_random_number(0, 1000000)
playtime = make_random_number(0, 15)
user_id = make_random_number(0, 1000000)
timestamp = make_datetime_now()
interest = "test_first"
datum = {
"board_id" : board_id,
"playtime" : playtime,
"user_id" : user_id,
"timestamp" : timestamp,
"interest" : "test_fluentd_firehose"
}
return datum
def make_datum_to_json(datum):
return json.dumps(datum)
def write_datum_json_to_file(datum, file_name):
with open(file_name, 'a') as file_object:
file_object.write(datum)
file_object.write("\n")
def send_record_to_kinesis(record):
'''
parameter: record
전달된 파라미터를 aws kinesis의 data로 넣어 전달합니다.
'''
kinesis = get_kinesis_client()
response = kinesis.put_record(
StreamName="test-seongwoo-data-stream",
Data=json.dumps(record, ensure_ascii=False),
PartitionKey="test-seongwoo-data-stream"
)
return response
def send_records_to_kinesis(records_list):
'''
parameter: record
전달된 파라미터를 aws kinesis의 data로 넣어 전달합니다.
'''
kinesis = get_kinesis_client()
response = kinesis.put_records(
StreamName="test-seongwoo-data-stream",
Records=records_list
)
print("size record: {}".format(sys.getsizeof(records_list)))
return response
def main():
data = list()
for j in range(0, 10):
datum = make_datum()
#print(datum)
datum_json = make_datum_to_json(datum)
write_datum_json_to_file(datum_json, "source/size_test.log")
data.append(datum_json)
#time.sleep(1)
#print(data)
payload_data = {"data":data}
print(send_record_to_kinesis(payload_data))
print(payload_data)
if __name__ == "__main__":
main()
$ conect_data_poc python data_generator_send_to_kinesis.py
{'ShardId': 'shardId-000000000012', 'SequenceNumber': '', 'ResponseMetadata': {'RequestId': '', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '', 'x-amz-id-2': '', 'date': 'Fri, 29 Nov 2019 09:58:27 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '110'}, 'RetryAttempts': 0}}
{'data': ['{"board_id": 367544, "playtime": 5, "user_id": 135009, "timestamp": "2019-06-03T02:08:38Z", "interest": "test_fluentd_firehose"}', '{"board_id": 99170, "playtime": 13, "user_id": 838639, "timestamp": "2019-01-02T12:15:59Z", "interest": "test_fluentd_firehose"}', '{"board_id": 101656, "playtime": 11, "user_id": 125452, "timestamp": "2019-03-20T01:22:02Z", "interest": "test_fluentd_firehose"}', '{"board_id": 66312, "playtime": 9, "user_id": 358120, "timestamp": "2019-11-12T09:13:01Z", "interest": "test_fluentd_firehose"}', '{"board_id": 521844, "playtime": 3, "user_id": 964657, "timestamp": "2019-04-02T01:54:25Z", "interest": "test_fluentd_firehose"}', '{"board_id": 188015, "playtime": 2, "user_id": 344103, "timestamp": "2019-08-12T15:29:47Z", "interest": "test_fluentd_firehose"}', '{"board_id": 375652, "playtime": 14, "user_id": 344086, "timestamp": "2019-11-26T05:47:31Z", "interest": "test_fluentd_firehose"}', '{"board_id": 128579, "playtime": 8, "user_id": 295529, "timestamp": "2019-03-27T19:05:28Z", "interest": "test_fluentd_firehose"}', '{"board_id": 193712, "playtime": 4, "user_id": 465238, "timestamp": "2019-01-11T00:39:18Z", "interest": "test_fluentd_firehose"}', '{"board_id": 215981, "playtime": 0, "user_id": 518551, "timestamp": "2019-06-17T09:03:27Z", "interest": "test_fluentd_firehose"}']}
AWS Lambda 생성 및 코드 등록
AWS 공식 문서를 참고하면, Firehose에 Lambda를 트리거해서 데이터를 변환할 경우 블루프린트를 사용해 생성하는 것을 권장하고 있다. 따라서, 아래 그림을 참고해 Lambda를 생성한다.
생성 후에는 Lambda console에서 함수 코드를 바로 수정할 수 있는데 아래와 같이 lambda_function.py를 수정한다. Lambda는 이벤트 발생시 트리거되어 실행되며 List로 되어있는 Records를 1개씩 분리해 정해진 룰에 맞는 Record로 변환된다. 변환 후 List로 만든 후 ‘records’ 의 밸류로 넣어 리턴한다.
from __future__ import print_function
from io import StringIO
import base64
import json
print('Loading function')
def lambda_handler(event, context):
output = []
print("event: {}".format(event))
for record in event['records']:
print("record['data'] : {}".format(record['data']))
payload = base64.b64decode(record['data'])
print("payload : {}".format(payload))
i = 0
utf_data = payload.decode("utf-8").replace('\\"',"'")
print("utf_data: {}".format(utf_data))
print("utf_data type: {}".format(type(utf_data)))
print("json.load(utf_data): {}".format(json.loads(utf_data)))
print("type json.load(utf_data): {}".format(type(json.loads(utf_data))))
utf_data_dict = json.loads(utf_data)
print(utf_data_dict['data'])
print(utf_data_dict['data'][0])
data_list = utf_data_dict['data']
# Do custom processing on the payload here
for data in data_list:
print("data type: {}".format(type(data)))
print(json.dumps(data))
data = data.encode("utf-8")
print("data endcode utf-8 type: {}".format(data))
output_record = {
'recordId': record['recordId']+str(i),
'result': 'Ok',
'data': base64.b64encode(data)
}
i += 1
output.append(output_record)
print(output)
print('Successfully processed {} records.'.format(len(event['records'])))
print("type output: {}".format(type(output)))
print("output: {}".format(output))
return {'records': output}
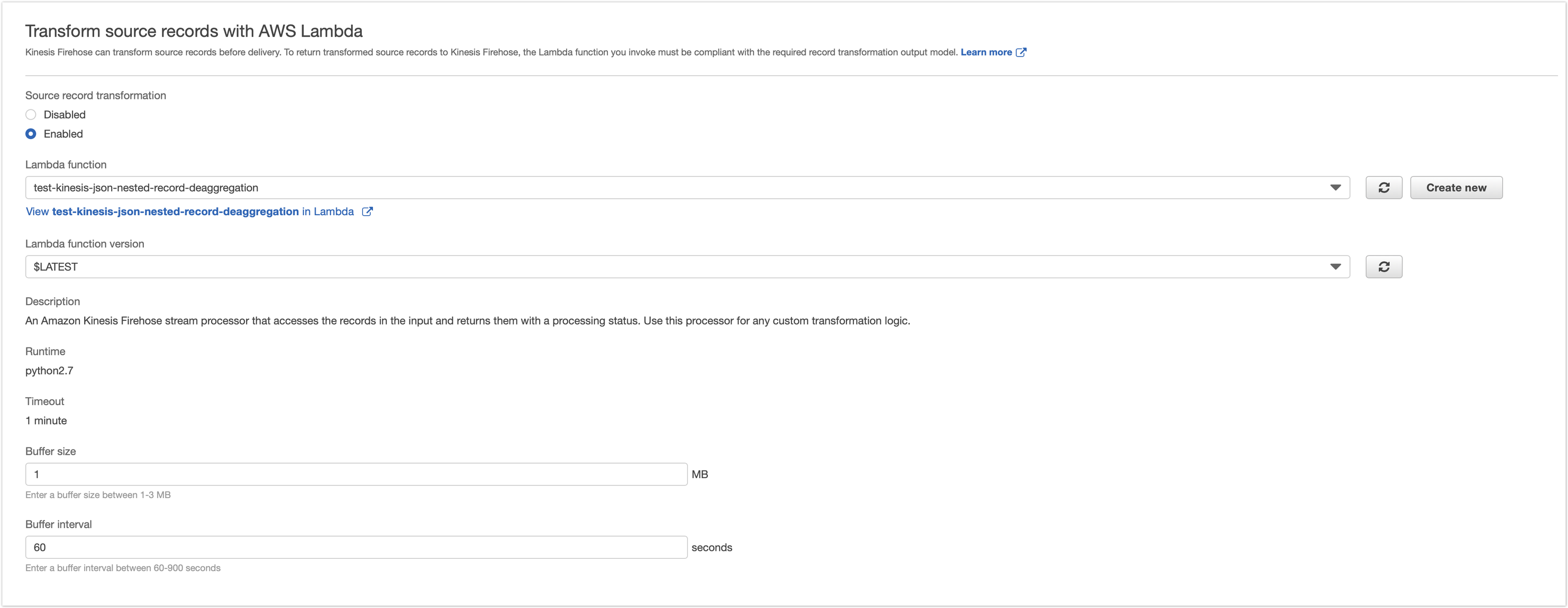
Firehose에 생성한 Lambda 트리거 설정하기
AWS Kinesis firehose에 lambda를 트리거하기 위해 아래와 같이 설정한다. 원활한 테스트를 위해 Buffer size 1, Buffer interval 60 seconds로 설정한다.
Data generator 실행, 테스트 결과 확인하기
Data generator를 실행해 AWS Kinesis Data stream으로 데이터를 입력한다.
$ conect_data_poc python data_generator_send_to_kinesis.py
입력 후 지정한 S3 버킷을 확인한다. 테스트에서는 sw-test123 버킷을 사용했다. 해당 버킷에 보면 Firehose에 트리거된 Lambda가 실패해 다음과 같은 경로에 파일이 저장되어 있음을 확인할 수 있다.
- sw-test123/processing-failed/2019/11/29/09
해당 파일의 내용은 다음과 같다.
{"attemptsMade":1,"arrivalTimestamp":1575020067711,"errorCode":"Lambda.MissingRecordId","errorMessage":"One or more record Ids were not returned. Ensure that the Lambda function returns all received record Ids.","attemptEndingTimestamp":1575020129986,"rawData":"eyJkYXRhIjogWyJ7XCJib2FyZF9pZFwiOiAyOTcxMywgXCJwbGF5dGltZVwiOiA5LCBcInVzZXJfaWRcIjogNjM2MTU2LCBcInRpbWVzdGFtcFwiOiBcIjIwMTktMDEtMjZUMTU6Mjg6MzVaXCIsIFwiaW50ZXJlc3RcIjogXCJ0ZXN0X2ZsdWVudGRfZmlyZWhvc2VcIn0iLCAie1wiYm9hcmRfaWRcIjogNTg0NzA3LCBcInBsYXl0aW1lXCI6IDksIFwidXNlcl9pZFwiOiAyMDY0OTcsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0xMC0wMlQxNzo0OTo0OFpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA2NTU4NzEsIFwicGxheXRpbWVcIjogOSwgXCJ1c2VyX2lkXCI6IDUyMjAzNywgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTAyLTIwVDA4OjIzOjM0WlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9IiwgIntcImJvYXJkX2lkXCI6IDg5OTUwMSwgXCJwbGF5dGltZVwiOiAxLCBcInVzZXJfaWRcIjogMjAyNDIsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wNi0wN1QxNzoxODo0N1pcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiAxODA3MDUsIFwicGxheXRpbWVcIjogOCwgXCJ1c2VyX2lkXCI6IDM2OTEyLCBcInRpbWVzdGFtcFwiOiBcIjIwMTktMDctMjlUMDk6MjE6MzJaXCIsIFwiaW50ZXJlc3RcIjogXCJ0ZXN0X2ZsdWVudGRfZmlyZWhvc2VcIn0iLCAie1wiYm9hcmRfaWRcIjogNjA2ODQ4LCBcInBsYXl0aW1lXCI6IDgsIFwidXNlcl9pZFwiOiA5OTMxMTgsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wNC0xNFQxODo1NToxOFpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiAzNDAwNTMsIFwicGxheXRpbWVcIjogOSwgXCJ1c2VyX2lkXCI6IDcwNzM1OCwgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTEyLTE2VDA1OjM5OjA2WlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9IiwgIntcImJvYXJkX2lkXCI6IDc4MzA3MywgXCJwbGF5dGltZVwiOiA2LCBcInVzZXJfaWRcIjogNTIwNjcsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wOC0yN1QxMTo0MToxM1pcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA3NDA0NzksIFwicGxheXRpbWVcIjogMTMsIFwidXNlcl9pZFwiOiAxNTI5NDMsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wNi0yNVQxNDoyMjoyOVpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA2MTQ2NTksIFwicGxheXRpbWVcIjogMTQsIFwidXNlcl9pZFwiOiA5NDIsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0xMC0yOFQyMTozMjozOVpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSJdfQ==","lambdaArn":""}
결과를 통해 Lambda의 Event로 처음 들어온 RecordId가 없거나 변경 되었을 경우 오류가 발생한다는 것을 확인할 수 있다.
따라서, Lambda의 코드를 다음과 같이 수정한다. 다음 코드는 1번째 Record는 기존 Record id를 넣고 나머지는 Record id에 번호를 붙여 저장하게 한 코드이다.
from __future__ import print_function
from io import StringIO
import base64
import json
print('Loading function')
def lambda_handler(event, context):
output = []
print("event: {}".format(event))
for record in event['records']:
print("record['data'] : {}".format(record['data']))
payload = base64.b64decode(record['data'])
#print(record['data'].decode("utf-8"))
#print("utf record['data']: {}".format(record['data'].decode("utf-8")))
print("payload : {}".format(payload))
#print("data : {}".format(payload[0]))
#print("data2 : {}".format(payload[0]['data']))
i = 0
utf_data = payload.decode("utf-8").replace('\\"',"'")
print("utf_data: {}".format(utf_data))
print("utf_data type: {}".format(type(utf_data)))
print("json.load(utf_data): {}".format(json.loads(utf_data)))
print("type json.load(utf_data): {}".format(type(json.loads(utf_data))))
utf_data_dict = json.loads(utf_data)
print(utf_data_dict['data'])
print(utf_data_dict['data'][0])
data_list = utf_data_dict['data']
# Do custom processing on the payload here
for data in data_list:
#payload['interest'] = "lambda_call"
print("data type: {}".format(type(data)))
print(json.dumps(data))
data = data.encode("utf-8")
#data = json.dump(data)
print("data endcode utf-8 type: {}".format(data))
if i == 0:
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(data)
}
else:
output_record = {
'recordId': record['recordId']+str(i),
'result': 'Ok',
'data': base64.b64encode(data)
}
i += 1
output.append(output_record)
print(output)
print('Successfully processed {} records.'.format(len(event['records'])))
#json.dumps(output)
print("type output: {}".format(type(output)))
print("output: {}".format(output))
return {'records': output}
결과는 다음과 같다.
{'board_id': 367544, 'playtime': 5, 'user_id': 135009, 'timestamp': '2019-06-03T02:08:38Z', 'interest': 'test_fluentd_firehose'}
결과를 통해 처음 1개의 List로 묶인 Record에 할당된 Record id를 제외한 나머지 Records는 결과를 리턴해도 저장하지 않는다는 것을 알 수 있다.
이번에는 분리된 모든 Records에 처음 들어온 Record id를 할당해본다. 테스트를 위해 Lambda의 코드를 다음과 같이 수정한다.
from __future__ import print_function
from io import StringIO
import base64
import json
print('Loading function')
def lambda_handler(event, context):
output = []
print("event: {}".format(event))
for record in event['records']:
print("record['data'] : {}".format(record['data']))
payload = base64.b64decode(record['data'])
#print(record['data'].decode("utf-8"))
#print("utf record['data']: {}".format(record['data'].decode("utf-8")))
print("payload : {}".format(payload))
#print("data : {}".format(payload[0]))
#print("data2 : {}".format(payload[0]['data']))
i = 0
utf_data = payload.decode("utf-8").replace('\\"',"'")
print("utf_data: {}".format(utf_data))
print("utf_data type: {}".format(type(utf_data)))
print("json.load(utf_data): {}".format(json.loads(utf_data)))
print("type json.load(utf_data): {}".format(type(json.loads(utf_data))))
utf_data_dict = json.loads(utf_data)
print(utf_data_dict['data'])
print(utf_data_dict['data'][0])
data_list = utf_data_dict['data']
# Do custom processing on the payload here
for data in data_list:
#payload['interest'] = "lambda_call"
print("data type: {}".format(type(data)))
print(json.dumps(data))
data = data.encode("utf-8")
#data = json.dump(data)
print("data endcode utf-8 type: {}".format(data))
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(data)
}
i += 1
output.append(output_record)
print(output)
print('Successfully processed {} records.'.format(len(event['records'])))
#json.dumps(output)
print("type output: {}".format(type(output)))
print("output: {}".format(output))
return {'records': output}
결과는 다음과 같다.
{"attemptsMade":1,"arrivalTimestamp":1575019718303,"errorCode":"Lambda.DuplicatedRecordId","errorMessage":"Multiple records were returned with the same record Id. Ensure that the Lambda function returns a unique record Id for each record.","attemptEndingTimestamp":1575019781231,"rawData":"eyJkYXRhIjogWyJ7XCJib2FyZF9pZFwiOiAxODgzMDMsIFwicGxheXRpbWVcIjogMiwgXCJ1c2VyX2lkXCI6IDY1MTA4OCwgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTA3LTExVDE1OjUwOjI5WlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9IiwgIntcImJvYXJkX2lkXCI6IDY2NzY5MywgXCJwbGF5dGltZVwiOiAxMywgXCJ1c2VyX2lkXCI6IDI5MDAyMywgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTAxLTI1VDE4OjM5OjUzWlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9IiwgIntcImJvYXJkX2lkXCI6IDU2MDMsIFwicGxheXRpbWVcIjogMTMsIFwidXNlcl9pZFwiOiA4NzA3MzgsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wNi0xNlQwNzo1OTo0M1pcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA4MTUxMCwgXCJwbGF5dGltZVwiOiAxMywgXCJ1c2VyX2lkXCI6IDY3OTkzMywgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTAyLTE1VDIzOjE5OjMyWlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9IiwgIntcImJvYXJkX2lkXCI6IDE3MjM1MSwgXCJwbGF5dGltZVwiOiAxMywgXCJ1c2VyX2lkXCI6IDYzMjExNywgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTAxLTIzVDIyOjAwOjQxWlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9IiwgIntcImJvYXJkX2lkXCI6IDczODc4LCBcInBsYXl0aW1lXCI6IDE0LCBcInVzZXJfaWRcIjogNjQzODI2LCBcInRpbWVzdGFtcFwiOiBcIjIwMTktMDItMjZUMjE6Mzk6MzhaXCIsIFwiaW50ZXJlc3RcIjogXCJ0ZXN0X2ZsdWVudGRfZmlyZWhvc2VcIn0iLCAie1wiYm9hcmRfaWRcIjogMzgzODkzLCBcInBsYXl0aW1lXCI6IDEsIFwidXNlcl9pZFwiOiA2NTE0NTcsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wNy0xNVQxODo1Mjo1NlpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA4NDQ5MTEsIFwicGxheXRpbWVcIjogMTMsIFwidXNlcl9pZFwiOiAzMjk2OTksIFwidGltZXN0YW1wXCI6IFwiMjAxOS0xMC0xMVQwNzoxNzozOFpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA5NzU4NTEsIFwicGxheXRpbWVcIjogMTIsIFwidXNlcl9pZFwiOiA5NTA5NDQsIFwidGltZXN0YW1wXCI6IFwiMjAxOS0wOC0xM1QxNDowNzozNVpcIiwgXCJpbnRlcmVzdFwiOiBcInRlc3RfZmx1ZW50ZF9maXJlaG9zZVwifSIsICJ7XCJib2FyZF9pZFwiOiA0ODIxODgsIFwicGxheXRpbWVcIjogMCwgXCJ1c2VyX2lkXCI6IDkzNTI2MSwgXCJ0aW1lc3RhbXBcIjogXCIyMDE5LTA1LTAzVDAwOjE4OjQyWlwiLCBcImludGVyZXN0XCI6IFwidGVzdF9mbHVlbnRkX2ZpcmVob3NlXCJ9Il19","lambdaArn":""}
결과를 통해 같은 Record id를 넣어 리턴할 경우 중복 id 오류가 발생한다는 것을 알 수 있다.
결론
테스트 결론 전 AWS 공식 사이트에서 다음과 같은 정보를 확인했다.
데이터 변환 및 상태 모델
Lambda의 모든 변환된 레코드에는 다음 파라미터가 포함되어 있어야 합니다. 그렇지 않으면 Kinesis Data Firehose가 이를 거부하고 데이터 변환 실패로 간주합니다.
recordId레코드 ID는 호출 중에 Kinesis Data Firehose에서 Lambda로 전달됩니다. 변환된 레코드에는 동일한 레코드 ID가 포함되어야 합니다. 원래 레코드의 ID와 변환된 레코드의 ID 간 불일치는 데이터 변환 실패로 간주됩니다. result레코드의 데이터 변환 상태입니다. 가능한 값은 Ok(레코드가 성공적으로 변환되었음), Dropped(처리 로직에 의해 의도적으로 레코드가 삭제됨), ProcessingFailed(레코드를 변환하지 못함)입니다. 레코드 상태가 Ok 또는 Dropped인 경우 Kinesis Data Firehose는 성공적으로 처리된 것으로 간주합니다. 그렇지 않으면 Kinesis Data Firehose에서 제대로 처리되지 않은 것으로 간주합니다. 데이터base64 인코딩 후 변환된 데이터 페이로드입니다.
테스트에서는 1개의 Record의 형태로 여러 개의 Record를 보내기 때문에 Firehose에 입력될 때 1개의 Record id가 할당이 되어 여러 개의 Record로 분리할 시 오류 또는 1개의 Record만 저장된다는 것을 알 수 있다.
테스트 결과를 기준으로 다음과 같은 결론을 내릴 수 있다.
- AWS Kinesis Data stream, AWS Kinesis Firehose로 구성된 환경에서 Lambda를 이용해 Firehose의 데이터를 수정할 수 있다. 그러나 List로 되어 있는 여러 개의 Records를 각각 분할해 여러 개의 Records로 만드는 것은 불가능하다.
댓글남기기